Disclosures during Red Team Exercise
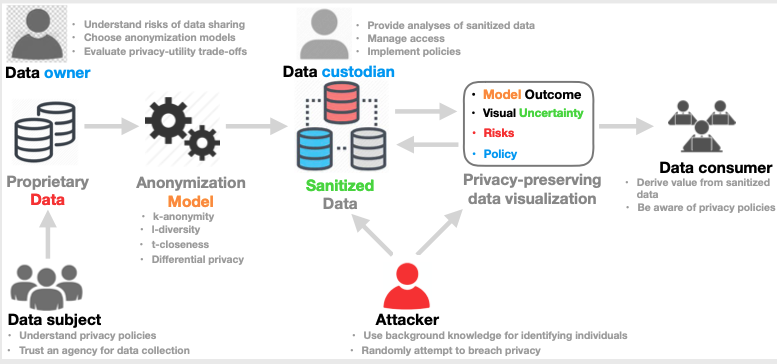
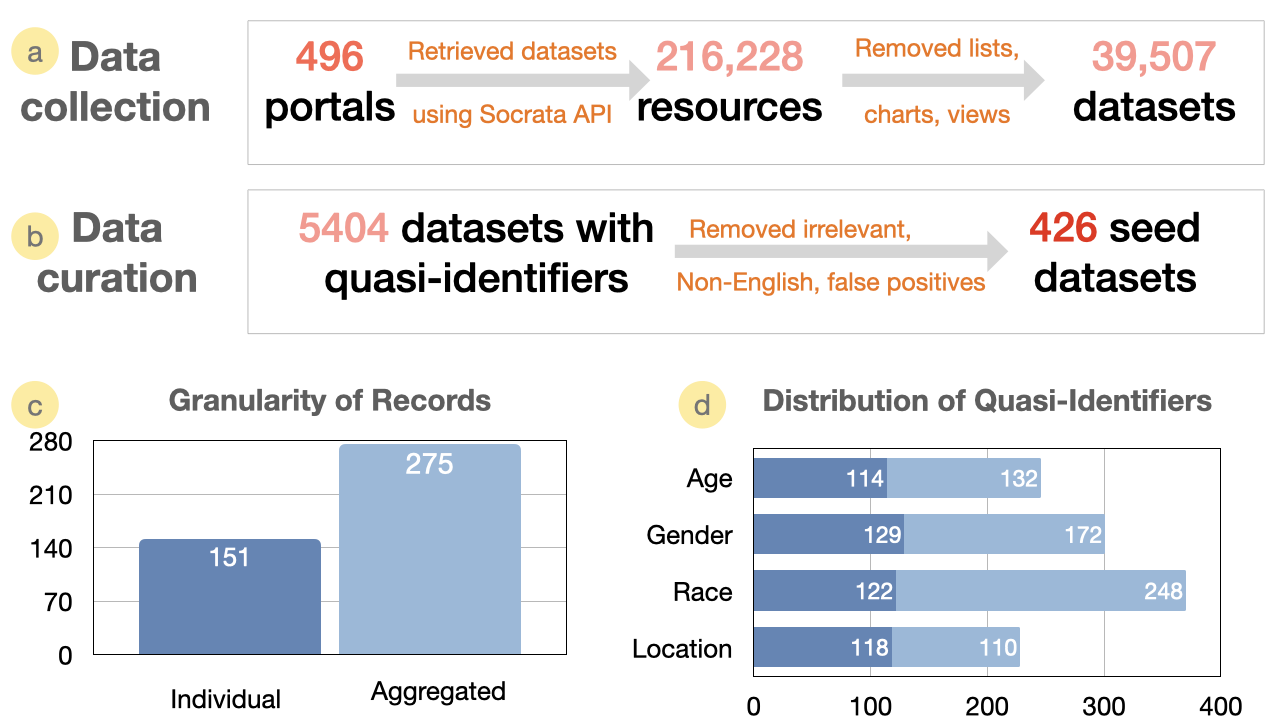
This paper highlights some of the vulnerabilities discovered during a red team exercise into the open data ecosystem. We report some examples where sensitive details of data subjects are exposed by joining open datasets.
Abstract: The open data ecosystem is susceptible to vulnerabilities due to disclosure risks. Though the datasets are anonymized during release, the prevalence of the release-and-forget model makes the data defenders blind to privacy issues arising after the dataset release. One such issue can be the disclosure risks in the presence of newly released datasets which may compromise the privacy of the data subjects of the anonymous open datasets. In this paper, we first examine some of these pitfalls through the examples we observed during a red teaming exercise and then envision other possible vulnerabilities in this context. We also discuss proactive risk monitoring, including developing a collection of highly susceptible open datasets and a visual analytic workflow that empowers data defenders towards undertaking dynamic risk calibration strategies.
[Details] [Paper]