TRIVEA
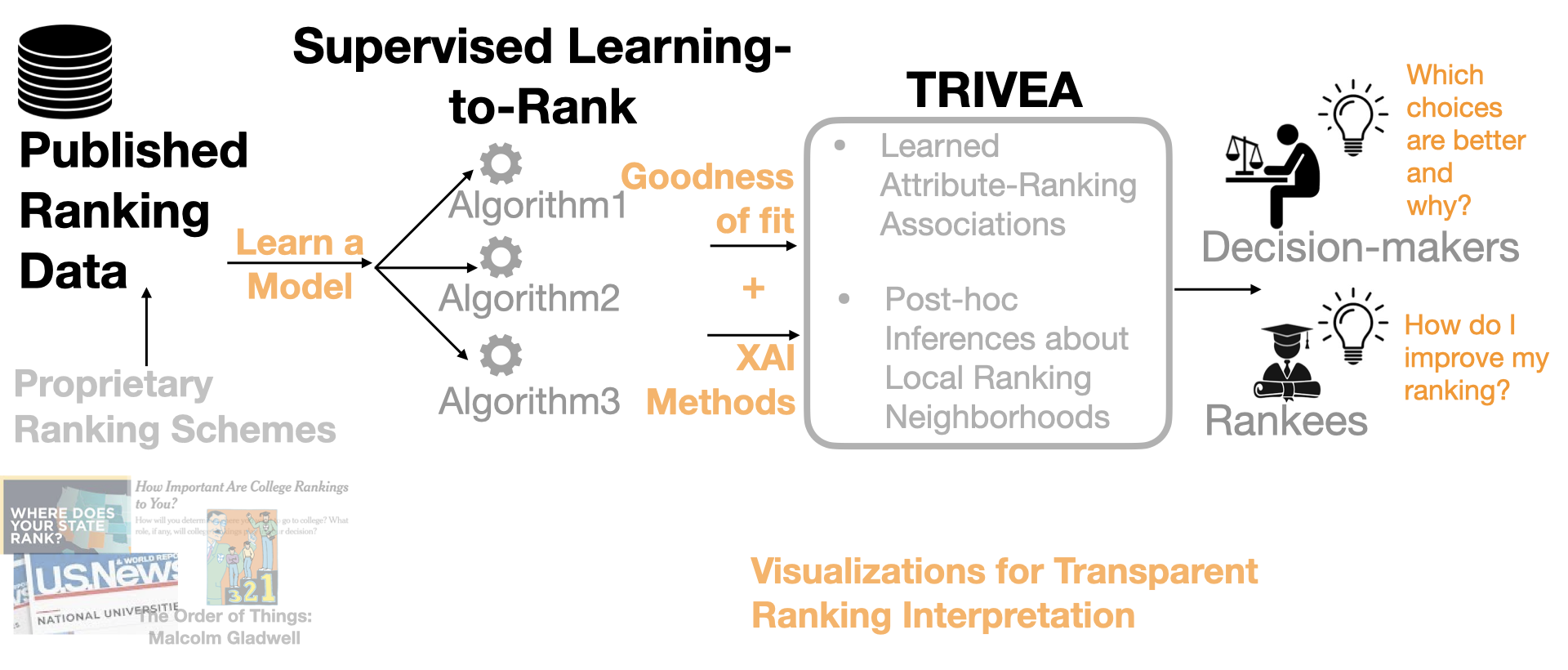
We created a web interface to help demystifying the pripietory rankings (e.g., US news Univeristy Rankings) using Learning-to-rank machine learning models and XAI methods (e.g., LIME, SHAP).
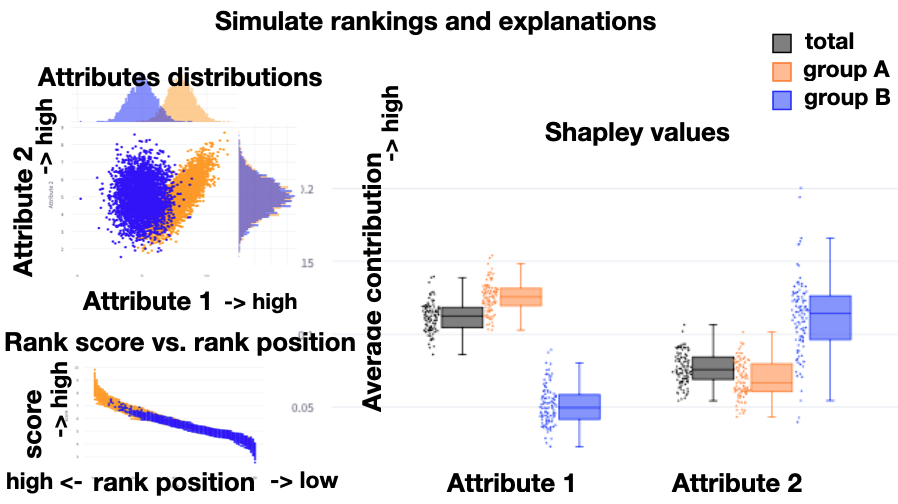
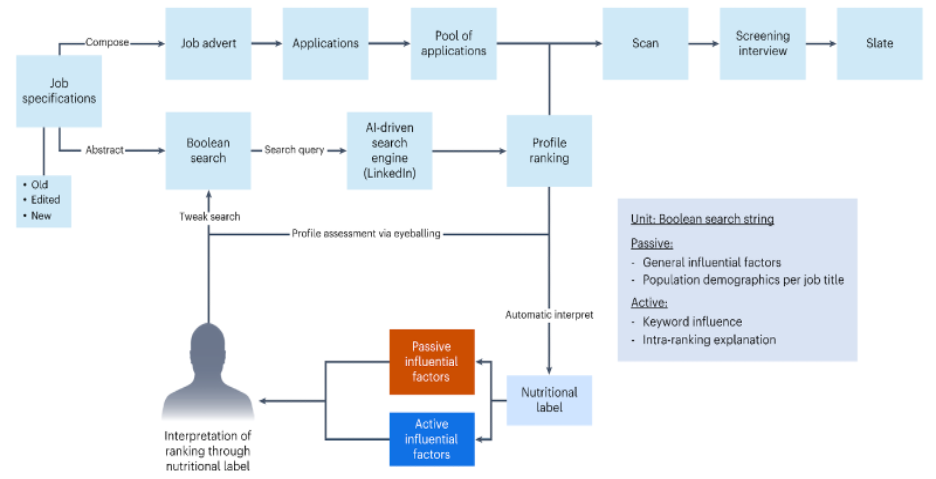
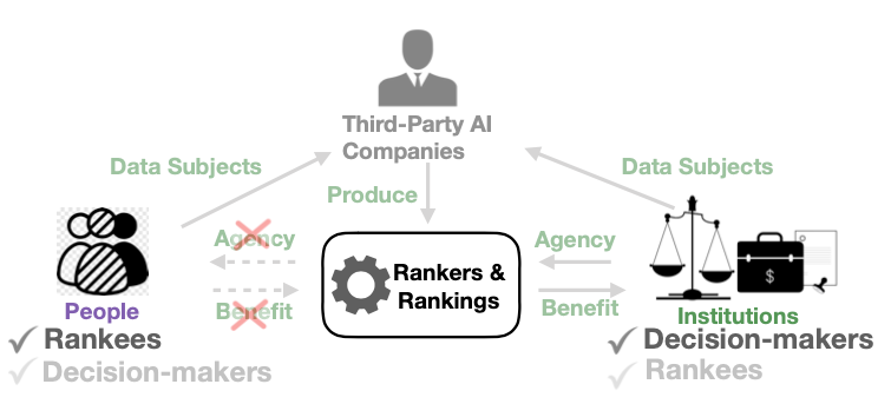
Abstract: Ranking schemes drive many real-world decisions, like, where to study, whom to hire, what to buy, etc. Many of these decisions often come with high consequences. For example, a university can be deemed less prestigious if not featured in a top-k list, and consumers might not even explore products that do not get recommended to buyers. At the heart of most of these decisions are opaque ranking schemes, which dictate the ordering of data entities, but their internal logic is inaccessible or proprietary. Drawing inferences about the ranking differences is like a guessing game to the stakeholders, like, the rankees (i.e., the entities who are ranked, like product companies) and the decision-makers (i.e., who use the rankings, like buyers). In this paper, we aim to enable transparency in ranking interpretation by using algorithmic rankers that learn from available data and by enabling human reasoning about the learned ranking differences using explainable AI (XAI) methods. To realize this aim, we leverage the exploration-explanation paradigm of human-data interaction to let human stakeholders explore subsets and groupings of complex multi-attribute ranking data using visual explanations of model fit and attribute influence on rankings. We realize this explanation paradigm for transparent ranking interpretation in TRIVEA, a visual analytic system that is fueled by: i) visualizations of model fit derived from algorithmic rankers that learn the associations between attributes and rankings from available data and ii) visual explanations derived from XAI methods that help abstract important patterns, like, the relative influence of attributes in different ranking ranges. Using TRIVEA, end users not trained in data science have the agency to transparently reason about the global and local behavior of the rankings without the need to open black-box ranking models and develop confidence in the resulting attribute-based inferences. We demonstrate the efficacy of TRIVEA using multiple usage scenarios and subjective feedback from researchers with diverse domain expertise.
[Details] [Paper]